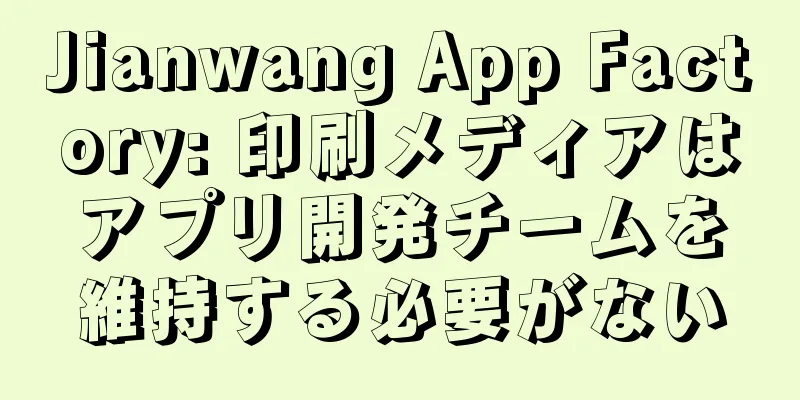
1. プロメテウスのアーキテクチャコンポーネントの紹介 - Prometheusサーバー: メトリックを収集し、時系列データを保存し、クエリインターフェースを提供します。
PushGateway: インジケーター データの短期保存。主に一時的なタスクに使用されます - エクスポーター: 監視データのソースであり、既存のサードパーティ サービス監視インジケーターを収集し、メトリックを公開します。共通監視ホストは、オンデマンドでインストールされる node-exporter と database mysql-exporter をインストールします。エクスポーターの場合、Prometheus サーバーはプルを使用してデータを収集します。
- Alertmanager: アラームをトリガーし、SMS、電子メールなどで送信します。
- Web UI: Grafanaをインストールし、Prometheusデータソースを構成することでダッシュボードを監視できるシンプルなWebコンソール
事前準備: 事前に Prometheus、grafana、node-exporter をデプロイします。ここでは詳しく説明しません。 ### 部署Prometheus docker run -d --name=prometheus -p 9090:9090 prom/prometheus #可以将配置文件访问地址:http://IP:9090 ### 部署Grafana docker run -d --name=grafana -p 3000:3000 grafana/grafana访问地址:http://IP:3000 ### 部署node-exporter ### wget https://github.com/prometheus/node_exporter/releases/download/v1.0.1/node_exporter-1.0.1.linux-amd64.tar.gz tar xvfz node_exporter-*.*-amd64.tar.gz cd node_exporter-*.*-amd64 ./node_exporter 2. 準備作業環境: Prometheus サーバーとアラートマネージャーは同じマシンにデプロイされています。実験の前提は、Prometheus サーバーがインストールされていることです。 オペレーティングシステム: CentOS 7.4 Prometheus のアラーム管理は 2 つの部分に分かれています。 Prometheus サーバーでアラーム ルールを設定すると、Prometheus サーバーはエクスポーターのデータ インジケーターを取得します。インジケーターがアラームしきい値を満たすと、これらのアラームは Alertmanager によって管理され、アラームの消音、抑制、集約、電子メール、エンタープライズ WeChat、DingTalk などを介したアラーム通知の送信などが含まれます。 アラートと通知を設定する主な手順は次のとおりです。 - Prometheus を 1 台のマシンにデプロイする (この記事では省略)
- ノードエクスポータ、監視対象となるすべてのノードをデプロイする必要がある(エージェントと同様)[この記事では省略]
- Prometheusと同じノードにAlertmanagerをインストールして起動します。
- Alertmanager にアクセスし、アラート ルールを構成するように Prometheus を構成します。
- WeChat Enterprise バックエンドを構成し、WeChat Enterprise に接続するようにアラートマネージャーを構成し、アラーム テンプレートを構成します。
- アラームをトリガーするためのしきい値を変更する
事前作業はオフラインパッケージを使用して展開することもできます ### 部署Prometheus #创建prometheus的docker-compose.yml的配置services: prometheus: command: - --web.listen-address=0.0.0.0:9090 - --config.file=/etc/prometheus/prometheus.yml - --storage.tsdb.path=/var/lib/prometheus - --storage.tsdb.retention.time=30d - --web.enable-lifecycle - --web.external-url=prometheus - --web.enable-admin-api container_name: prometheus deploy: resources: limits: cpus: '2' memory: 8g hostname: prometheus image: prom/prometheus labels: - docker-compose-reset=true - midware-group=monitor network_mode: host restart: always volumes: - /usr/share/zoneinfo/Hongkong:/etc/localtime - /data/prometheus/data:/var/lib/prometheus - /data/prometheus/config:/etc/prometheus working_dir: /var/lib/prometheus version: '3' #执行docker-compose up -d启动prometheus服务### 部署Grafana docker run -d --name=grafana -p 3000:3000 grafana/grafana访问地址:http://IP:3000 ### 部署node-exporter ### wget https://github.com/prometheus/node_exporter/releases/download/v1.0.1/node_exporter-1.0.1.linux-amd64.tar.gz tar xvfz node_exporter-*.*-amd64.tar.gz cd node_exporter-*.*-amd64 ./node_exporter
3. AlertManagerをインストールする公式サイトの最新バージョンを例にとると、公式サイトのアドレスhttps://prometheus.io/download/からアラートマネージャのインストールパッケージをダウンロードできます。 パッケージをサーバーにアップロードし、以下の手順に従ってalertmanagerサービスをインストールして起動します。 [root@localhost ~]# mkdir -p /data/alertmanager [root@localhost~]# tar -xvf alertmanager-0.22.2.linux-amd64.tar.gz -C /data/alertmanager [root@localhost~]# cd /data/alertmanager/ [root@localhost alertmanager]# nohup ./alertmanager & 4. Prometheusアラームルールを設定するPrometheus に構成監視アラートマネージャ サーバーを追加する prometheus.ymlに次の設定を追加します。 alerting: alertmanagers: - static_configs: - targets: - 192.168.61.123:9093 rule_files: - "rules/*_rules.yml" - "rules/*_alerts.yml" scrape_configs: - job_name: 'alertmanager' #配置alertmanager,等alertmanager部署后配置static_configs: - targets: ['localhost:9093'] - job_name: 'node_exporter' #配置node-exporter static_configs: - targets: ['192.168.61.123:9100'] rule_filesはアラームをトリガーするためのルールファイルです prometheus の現在のパスの下に新しいルール ディレクトリを作成し、次の構成ファイルを作成して、ノード アラームとポッド コンテナ アラームをそれぞれ構成します。 [root@prometheus prometheus]# cd rules/ [root@prometheus rules]# ls node_alerts.yml pod_rules.yml node_alerts.yml #ホストレベルのアラームを監視する [root@localhost rules]# cat node_alerts.yml groups: - name: 主机状态-监控告警rules: - alert: 主机状态expr: up {job="kubernetes-nodes"} == 0 for: 15s labels: status: 非常严重annotations: summary: "{{.instance}}:服务器宕机" description: "{{.instance}}:服务器延时超过15s" - alert: CPU使用情况expr: 100-(avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by(instance)* 100) > 60 for: 1m labels: status: warning annotations: summary: "{{$labels.instance}}: High CPU Usage Detected" description: "{{$labels.instance}}: CPU usage is {{$value}}, above 60%" - alert: NodeFilesystemUsage expr: 100 - (node_filesystem_free_bytes{fstype=~"ext4|xfs"} / node_filesystem_size_bytes{fstype=~"ext4|xfs"} * 100) > 80 for: 1m labels: severity: warning annotations: summary: "Instance {{ $labels.instance }} : {{ $labels.mountpoint }} 分区使用率过高" description: "{{ $labels.instance }}: {{ $labels.mountpoint }} 分区使用大于80% (当前值: {{ $value }})" - alert: 内存使用expr: (node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes) / node_memory_MemTotal_bytes * 100 > 80 for: 1m labels: status: 严重告警annotations: summary: "{{ $labels.instance}} 内存使用率过高!" description: "{{ $labels.instance }} 内存使用大于80%(目前使用:{{ $value}}%)" - alert: IO性能expr: (avg(irate(node_disk_io_time_seconds_total[1m])) by(instance)* 100) > 60 for: 1m labels: status: 严重告警annotations: summary: "{{$labels.instance}} 流入磁盘IO使用率过高!" description: "{{ $labels.instance }} 流入磁盘IO大于60%(目前使用:{{ $value }})"
pod_rules.yml ファイル構成 #pod レベルアラーム [root@localhost rules]# cat pod_rules.yml groups: - name: k8s_pod.rules rules: - alert: pod-status expr: kube_pod_container_status_running != 1 for: 5s labels: severity: warning annotations: description : pod-{{ $labels.pod }}故障summary: pod重启告警- alert: Pod_all_cpu_usage expr: (sum by(name)(rate(container_cpu_usage_seconds_total{image!=""}[5m]))*100) > 10 for: 5m labels: severity: critical service: pods annotations: description: 容器{{ $labels.name }} CPU 资源利用率大于75% , (current value is {{ $value }}) summary: Dev CPU 负载告警- alert: Pod_all_memory_usage expr: sort_desc(avg by(name)(irate(container_memory_usage_bytes{name!=""}[5m]))*100) > 1024*10^3*2 for: 10m labels: severity: critical annotations: description: 容器{{ $labels.name }} Memory 资源利用率大于2G , (current value is {{ $value }}) summary: Dev Memory 负载告警- alert: Pod_all_network_receive_usage expr: sum by (name)(irate(container_network_receive_bytes_total{container_name="POD"}[1m])) > 1024*1024*50 for: 10m labels: severity: critical annotations: description: 容器{{ $labels.name }} network_receive 资源利用率大于50M , (current value is {{ $value }}) summary: network_receive 负载告警
さらなる警告ルール[Scientific Internet Access] https://samber.github.io/awesome-prometheus-alerts/rules for 句: Prometheus は、expr 内のルールをトリガー条件として使用します。この場合、Prometheus はアラートをトリガーする前に、アラートが引き続きアクティブであるかどうかを毎回確認します。アクティブだがまだトリガーされていない要素は保留状態になります。 for で定義された時間は、アラームがトリガーされる前のアクティブ状態の継続時間です。 設定を追加したら、Prometheusサービスをホットリスタートします。 curl -XPOST http://localhost:9090/-/reload 注: prometheus 起動コマンドに --web.enable-lifecycle パラメータを追加すると、ホット リスタートをサポートできます。 $ ./promtool check config prometheus.yml Checking prometheus.yml SUCCESS: 0 rule files found 上記のコマンドは、設定ファイルの変更が正しいかどうかを確認できます。 プロメテウスターゲットインターフェースにログインすると、アラートマネージャの監視オブジェクトが表示されます。 Prometheusアラームルール設定が有効かどうかを確認する ノードとポッドの監視インジケーターが読み込まれていることがわかります。完璧、成功に一歩近づいた 5. アラートを送信するようにAlertManagerを設定するエンタープライズWeChatアラーム通知を実装するには、まずエンタープライズバックグラウンドでprometheusという名前のアプリケーションを作成する必要があります。 後で構成ファイルで必要になる会社 ID、シークレット、エージェント ID 情報を記録します。 [root@localhost alertmanager]# cat alertmanager.yml global: resolve_timeout: 1m # 每1分钟检测一次是否恢复wechat_api_url: 'https://qyapi.weixin.qq.com/cgi-bin/' wechat_api_corp_id: 'xxxxxxxxx' # 企业微信中企业ID wechat_api_secret: 'xxxxxxxx' templates: - '/data/alertmanager/template/*.tmpl' route: receiver: 'wechat' group_by: ['env','instance','type','group','job','alertname'] group_wait: 10s group_interval: 5s repeat_interval: 1h receivers: - name: 'wechat' wechat_configs: - send_resolved: true message: '{{ template "wechat.default.message" . }}' to_party: '57' agent_id: 'xxxx' #企微后台查询的agentid to_user : "@all" api_secret: 'xxxxxxx' #后台查询的secret 例示する - wechat_api_urlはWeChat for Enterpriseのインターフェースアドレスとして設定されているため、alertmanagerが配置されているサーバーはパブリックネットワークに接続できる必要があります。
- to_user を設定する必要があります。 all は、表示されているすべてのユーザーにアラートを送信することを意味します。このタグがないと、アラートを送信できません。自分でテストしてみました。エンタープライズ マイクロ バックエンドの表示範囲には、アラートを受信するユーザーを追加できます。
- フィールドの説明
- グローバル: グローバル設定
- resolve_timeout: アラーム回復タイムアウト。受信したアラームに EndsAt フィールドがない場合、アラームはこの時間後に解決済みとしてマークされます。 Prometheus では使用されません。アラームには EndsAt フィールドが含まれます。
- ルート: アラーム配信設定
- group_by: グループ化ラベルを設定します。アラームに表示されるラベルはグループ化に使用できます。異なるラベルをすべてグループ化する必要がある場合は、「…」を使用できます。
- group_wait: アラーム送信の待機時間。アラームの集約には、時間が長いほど便利です。
- group_interval: 2つのアラームグループを送信する間隔
- repeat_interval: 繰り返しアラームを送信する間隔
- 受信機: アラームを受信するオブジェクトを定義します
- 受信機:アラーム受信機。この情報を取得するには、手順 1 を参照してください。
- name: ルート内の受信機に対応するアラーム受信機の名前。ここではWeChat for Enterpriseを設定します
- corp_id: 企業 WeChat の固有 ID、My Company -> 企業情報
- to_party: アラームを送信するグループ
- agent_id: 作成したアプリケーションの ID。作成したアプリケーションの詳細をページで確認できます。
- api_secret: 独自のアプリケーションを作成するためのキー。作成したアプリケーションの詳細ページで確認できます。
- send_resolved: アラームが解決されたときに通知を送信するかどうか
- inhibit_rules: アラーム抑制ルール
新しいアラームが target_match ルールに一致し、送信されたアラームが source_match ルールを満たし、新しいアラームのラベルが送信されたアラームの equal フィールドで定義されたラベルと同じである場合、新しいアラームは抑制されます。 上記の構成の結果、同じアラート名アラームを持つ同じインスタンスに対して、major は警告アラームを抑制します。これは理解しやすいですね。たとえば、しきい値アラームが重大に達した場合は、警告にも達する必要があります。アラームを2回送信する必要はありません。 ただし、実際のテスト結果から、この抑制ルールはアラームがトリガーされた場合にのみ使用でき、アラームの回復には影響がないことがわかりました。それはバグである可能性があります、または私が使用しているバージョンが低すぎる可能性があります。時間があるときにソースコードを確認してみます。 テンプレート: アラームメッセージテンプレート エンタープライズWeChatアラーム送信テンプレート、現在のパスに新しいテンプレートディレクトリを作成します [root@localhost alertmanager]# cat template/wechat.tmpl {{ define "wechat.default.message" }} {{- if gt (len .Alerts.Firing) 0 -}} {{- range $index, $alert := .Alerts -}} {{- if eq $index 0 }} =========xxx环境监控报警=========告警状态:{{ .Status }}告警级别:{{ .Labels.severity }}告警类型:{{ $alert.Labels.alertname }}故障主机: {{ $alert.Labels.instance }} {{ $alert.Labels.pod }}告警主题: {{ $alert.Annotations.summary }}告警详情: {{ $alert.Annotations.message }}{{ $alert.Annotations.description}};触发阀值:{{ .Annotations.value }}故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} ========= = end = ========= {{- end }} {{- end }} {{- end }} {{- if gt (len .Alerts.Resolved) 0 -}} {{- range $index, $alert := .Alerts -}} {{- if eq $index 0 }} =========xxx环境异常恢复=========告警类型:{{ .Labels.alertname }}告警状态:{{ .Status }}告警主题: {{ $alert.Annotations.summary }}告警详情: {{ $alert.Annotations.message }}{{ $alert.Annotations.description}};故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}恢复时间: {{ ($alert.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} {{- if gt (len $alert.Labels.instance) 0 }}实例信息: {{ $alert.Labels.instance }} {{- end }} ========= = end = ========= {{- end }} {{- end }} {{- end }} {{- end }}
構成を変更したら、ホットリスタートを実行するコマンドを実行します。 curl -XPOST http://localhost:9093/-/reload 設定が完了したら、テスト用のアラームしきい値を調整できます。 /usr/local/prometheus/rules/node_alerts.yml のディスクアラームしきい値を変更します。 expr: 100 - (node_filesystem_free_bytes{fstype=~"ext4|xfs"} / node_filesystem_size_bytes{fstype=~"ext4|xfs"} * 100) > 10 警告するには>10に変更し、管理インターフェースにログインするとすぐにアラームが届きます。 ここでは、Prometheus Alert には、非アクティブ、保留中、および実行中の 3 つの状態があることを説明します。 - 非アクティブ: 非アクティブ状態。監視は進行中だが、アラームはトリガーされていないことを示します。
- 保留中: このアラームをトリガーする必要があることを示します。アラームはグループ化、抑制/禁止、または消音/サイレントにすることができるため、検証を待機し、すべての検証に合格すると、発火状態に移行します。
- 発火: アラートを AlertManager に送信します。AlertManager は、設定されたとおりにすべての受信者にアラートを送信します。アラームがクリアされると、状態は非アクティブに変更され、サイクルが継続されます。
完成しました。拍手をお願いします! |